1. Introducción
La información manejada por las empresas de recursos de hidrocarburos a través de sus distintos sistemas informáticos corresponde a datos históricos que se han incrementando con el pasar de los años. Analizar esta data en su totalidad a través de un experto humano constituye una labor prácticamente imposible. Por lo que se hace necesaria la incorporación de Nuevas Tecnologías de Información y Comunicación (NTIC) para apoyar los procesos de toma de decisiones de las gerencias encargadas de coordinar este tipo de sistema. Estas gerencias, por lo general, son las responsables de manejar la información de las reservas petrolíferas de sus respectivos países manteniendo un repositorio de datos muy amplio, el cual va constantemente actualizándose y creciendo. Cobran aún mayor importancia la responsabilidad de estas gerencias al ser la explotación de hidrocarburos una de las principales fuentes energéticas de las naciones del mundo y motivo de las mayores disertaciones en ámbitos económicos internacionales.
De este modo, el estudio de estas gerencias constituye un buen punto de partida para efectuar un proceso de extracción de conocimiento en base a datos históricos suficientemente representativos lo que permitirá la toma de decisiones más acertadas y efectivas ya que estará enfocada en las “experiencias” previas y memoria operativa de la organización. En consecuencia, en la presente investigación se planteó el diseño de un sistema de extracción de conocimiento para este tipo particular de gerencia, que ayude a obtener información validada en base a experiencias previas y valiosas para la toma de decisiones. La intención del sistema es marcar un curso de acción a partir del cual se pueden procesar datos provenientes de distintos repositorios y mediante determinados criterios de categorización y clasificación obtener una matriz de información nunca antes concebible e imposible de obtener si se pensara en un procesamiento manual. Esta matriz permitiría dilucidar patrones de datos insospechados idóneos para el establecimiento de la toma de decisiones gerencial.
El enfoque utilizado fue el descubrimiento de conocimiento a partir de grandes bases de datos (KDD: Knowledge Discovery in Databases), metodología actualmente aplicada de forma habitual para la toma eficiente de decisiones, basadas en experiencias previas, en las empresas e industrias. La industria petrolera no escapa a esta realidad y en base a la naturaleza y cantidad de información transaccional que procesa, susceptible de ser clasificada y categorizada desde múltiples e indefinidas categorías, tales como: datos exploratorios, producción en pozos, sometimiento de reservas, entre otros resulta ser una candidata ideal para este tipo de estudio.
SECRH-FOS: Sistema de Extracción de Conocimiento para Empresas de Recursos de Hidrocarburos basado en la Filosofía de Open Source, resulta ser entonces la solución a este tipo de problema. Su arquitectura se constituye en los procesos relativos a: preparación de datos, minería de datos y visualización, validación e interpretación. De forma más específica SECRH-FOS permitiría concentrar un gran volumen de datos proveniente de distintos repositorios, en un único almacén, el cual será organizado obedeciendo a los criterios del usuario que se propone realizar el análisis específico de una situación particular. Todo esto modelado bajo los casos de uso de la metodología OOSE: Object-Oriented Software Engineering de Jacobson (1998).
En este contexto, este diseño proporcionaría nuevas ventajas competitivas a la industria petrolera, ofreciendo la oportunidad de acceder a análisis de datos no previstos e imposibles de realizar con un procesamiento manual, dado la cantidad y dimensiones de los mismos, y estaría alineado con los objetivos de la soberanía tecnológica que se han propuesto muchas de las naciones latinas y europeas, por cuanto se trata de un desarrollo propio y basado en estándares abiertos.
Igualmente, la propuesta de un único almacén de datos traería beneficios adicionales a las empresas, al no poseer una data dispersa sino consolidada en un único punto y accesible para cualquier análisis que se requiera de la misma, también propiciaría investigaciones científicas (estudio a profundidad de características obtenidas) y mejoras en la calidad de la información que se está manejando actualmente; lo que a futuro conllevaría a expandir las áreas de exploración, optimizar los procesos de la cadena de valor de la industria (exploración, perforación y producción de pozos, basándose en las características, por ejemplo, petrofísicas y las correspondientes relaciones halladas), y permitiría obtener así una mayor reserva de hidrocarburos, aspecto este de vital importancia para la explotación petrolera.
2. Knowledge discovery in databases (KDD)
Knowledge Discovery in Databases (KDD) es una metodología para la obtención o extracción de información potencialmente útil que es desconocida, a partir de un almacén de datos. Con esta metodología se busca descubrir conocimiento nuevo, no confirmar o desmentir hipótesis.
En Daedalus (2001) se observa que los pasos a seguir para la realización de un proyecto de minería de datos son siempre los mismos, independientemente de la técnica específica de extracción de conocimiento usada. Éstos son: (a) preprocesado de los datos, (b) selección de las características, (c) uso de un algoritmo de extracción de conocimiento, y (d) interpretación y evaluación.
No obstante, se debe aclarar que al ser la minería de datos la fase del KDD que realiza la generación de hipótesis, generalmente se confunde KDD con Data Mining, es por ello que se establecen las fases de la metodología de KDD de una forma más detallada y específica. Las primeras fases del KDD, permiten que las subsiguientes fases, puedan extraer conocimiento útil y válido, a partir de la fuente original de información. A continuación, se presentan el conjunto de fases del KDD, establecidas por Hernández (s.f.).
Primera Fase. Recolección de Datos.
Consiste en la determinación de las fuentes de información que pueden ser útiles y el lugar de origen de las mismas, el diseño del almacén de datos y su posterior implantación, a fin de que permita la visualización previa de los datos. Sobre el almacén de datos, en PMSI (s.f.) se establece que el data mining no depende de la organización de los datos; pueden ser archivos tradicionales, las bases de datos o el Data Warehouse.
Generalmente, la información que se desea investigar, se encuentra en: bases de datos y otras fuentes diversas, que pueden ser tanto internas como externas, y muchas de ellas son las que se emplean para el trabajo con transacciones. Las fases posteriores (especialmente aquellas relacionadas con el análisis de la data) serán más sencillas si la fuente es unificada, accesible (interna) y desconectada del trabajo transaccional.
Segunda Fase. Selección, Limpieza y Transformación de Datos.
Se deben eliminar el mayor número de datos inconsistentes o erróneos (limpieza) e irrelevantes (selección). La selección implica unir varias tablas relacionales, archivos de transacciones, etc., es decir, una fusión de filas y columnas. En esta fase se filtran los datos, de forma que se eliminen valores incorrectos, no válidos o desconocidos. Por último, la data seleccionada es transformada según las necesidades y el algoritmo a utilizar.
Tercera Fase. La Minería de datos (Data Mining).
Ésta es una etapa crucial, en la cual, se selecciona y aplica la técnica de Data Mining apropiada, para seleccionar la misma, influye en gran manera, por no decir exclusivamente, el tipo de conocimiento que se desea extraer de la data. Por esta razón, una vez recolectada la información de interés, se puede decidir qué tipo de patrón o patrones se quiere descubrir.
Cuarta Fase. Evaluación y Validación.
Una vez obtenidos los resultados, se debe proceder a su validación comprobando que los mismos sean válidos y suficientemente satisfactorios. En fin, se evalúan los patrones extraídos, para así identificar cuáles de ellos representan conocimiento.
Quinta Fase. Interpretación y Difusión.
Es la fase final, el conocimiento descubierto es visualmente presentado a los usuarios. Esta parte de la metodología, utiliza técnicas de visualización (gráficos, reportes, cuadros, etc.) para ayudarlos a entender e interpretar los resultados. Se difunde y utiliza el nuevo conocimiento.
3. Técnica de minería de datos
Para realizar la extracción de información útil, que no está representada explícitamente en los almacenes de datos, la minería de datos combina técnicas de análisis estadístico, inteligencia artificial, base de datos y de visualización, entre otros.
Las técnicas de minería de datos constituyen el resultado de un largo proceso de investigación y desarrollo de productos, que comenzó con la utilización de las computadoras para almacenar datos, y continuó a medida que se mejoraba el acceso a los mismos, y más recientemente con las tecnologías creadas para permitir a los usuarios navegar a través de ellos en tiempo real. Según PMSI (s.f.) las técnicas de Data Mining permiten ganar tanto en performance como en manejabilidad e incluso en tiempo de trabajo. La posibilidad de realizar uno mismo sus propios modelos, sin necesidad de sub-contratar ni ponerse de acuerdo con un estadístico, proporciona una gran libertad a los usuarios profesionales.
A continuación, se describen algunas de las técnicas de minería de datos más utilizadas:
Caracterización y discriminación. Para Daza (s.f.) es útil que los datos sean generalizados en diferentes niveles de abstracción, lo cual facilita a los usuarios el estudio general del comportamiento de los mismos. La caracterización, suministra un resumen breve de las características generales o principales rasgos de una colección de datos. La discriminación, constituye una comparación de las características generales de dos o más colecciones de datos.
Clasificación. En Hernández (s.f.) se expresa que la clasificación es el esclarecimiento de una dependencia, en la que el atributo dependiente puede tomar un valor entre varias clases ya conocidas. Siendo una dependencia, una relación en la que un patrón en que se definen una o más características (atributos) determinan el valor de otra. Es decir, consiste en clasificar un objeto basado en su descripción. Se basa en la selección de un grupo de objetos pertenecientes a la categoría dada e inducir (por medio de una máquina de aprendizaje) la descripción de esa categoría. Se suele emplear esta técnica, cuando se quiere hacer un diagnóstico, reconocer un patrón o describir una colección de datos.
- Reglas de asociación. Tal como se indica en Hernández (s.f.) esta técnica de minería de datos busca asociaciones fuertes o relaciones de correlación entre ítems en una enorme colección de datos. Una asociación entre dos atributos se da cuando la frecuencia de que se presenten dos valores determinados, de cada uno al mismo tiempo, es relativamente alta. Se basa en el descubrimiento de patrones frecuentes y con ellos generar las reglas de asociación.
- Agrupamiento/segmentación. Para Daza (s.f.) esta técnica analiza el agrupamiento de los datos, para lo cual se forman grupos de objetos de tal manera que un objeto dentro de un grupo tiene alto grado de similitud comparado con otro objeto del mismo grupo, pero son muy diferentes comparados con objetos de otros grupos.
4. SECRH: Sistema de extracción de conocimiento para empresas de hidrocarburos
Usando el modelo de casos de uso presentado en Jacobson (1998), se diseña SECRH-FOS: Sistema de Extracción de Conocimiento para Empresas de Recursos de Hidrocarburos, el cual interactúa con dos actores principales:
- Administrador de sistema: actor (primario) que tiene acceso a toda la información que es manejada por el sistema y puede realizar todas las operaciones presentadas.
- Base de Datos: actor (primario) que proporciona la información manejada por el sistema. Como puede observarse más adelante, la base de datos se generaliza en varios contenedores a partir los cuales es posible obtener información. Vale la pena aclarar, que se ha utilizado el término base de datos a objeto de emplear un concepto generalizado en el ambiente de sistemas de información, sin embargo, éste puede tomar, en la práctica, la forma de archivos, tablas u otra forma de almacenamiento.
Los casos de uso en los que se estructura SECRH-FOS se representan en la Fig. 1. Su significancia se explica brevemente a continuación:
Fig. 1. Diagrama de Casos de Uso para SECRH-FOS.

- Preparación de datos. Caso de uso que identifica las operaciones necesarias para la correcta delimitación, preparación y ajustes previos al proceso de los datos.
- Generar almacén de datos:comprende la delimitación y posterior generación de la estructura que constituye el nuevo almacén de datos o la actualización de uno previamente creado.
- Crear nuevo almacén: identifica la creación de la estructura de un nuevo almacén de datos, partiendo de las consideraciones suministradas por el usuario en cuanto al origen de la data (ejecución de un script, una base de datos en particular u otro tipo de archivo) y las restricciones a considerar (qué base de datos, tablas y/o campos va a tomar en cuenta, claves foráneas, etc.).
- Actualizar almacén: abarca la selección, ubicación y posterior actualización de un almacén de datos previamente creado.
- Depuración de datos:identifica la funcionalidad de refinar la data que se encuentra en el almacén de datos previamente creado, considerando las especificaciones que indicará el usuario antes de iniciar el proceso de depuración.
- Selección: representa la exclusión de las tablas y/o campos considerados (por el usuario) como irrelevantes para la realización del estudio.
- Limpieza: comprende la eliminación de aquellos datos inconsistentes o erróneos.
- Transformación: representa la funcionalidad de transformar (a un formato o valor indicado previamente) cierto conjunto de datos, tomando en cuenta las especificaciones o criterios indicados por el usuario.
- Datos anómalos: proceso de transformación de aquellos datos considerados como anómalos y que afectan la integridad de la data.
- Datos faltantes: proceso de transformación de aquellos datos ausentes y que generan inconsistencia en la información.
- Minería de datos. Caso de uso que comprende la selección y posterior aplicación de la técnica de Data Mining apropiada, dependiendo del tipo de conocimiento que se desee extraer de la data.
- Reglas de asociación: constituye la elección y aplicación de las reglas de asociación como técnica de minería de datos en el proceso de extracción de conocimientos a los datos delimitados y depurados.
- Segmentación: abarca la selección y posterior aplicación de la técnica de minería de datos segmentación para la ejecución del estudio en la data preparada anteriormente.
- Discriminación: representa la selección y posterior aplicación de la técnica de minería de datos discriminación para la ejecución del estudio en la data preparada anteriormente.
- Caracterización: identifica la selección y aplicación de la caracterización como técnica de minería de datos en la realización del estudio en la data previamente creada o seleccionada y preparada.
- Clasificación: identifica la selección de la clasificación como la técnica de minería de datos a ser aplicada durante la realización del estudio (extracción de conocimientos) en el almacén de datos considerado en casos de usos anteriores.
- Visualización, validación e interpretación. Una vez aplicado lo contemplado en el caso de uso Minería de Datos, se da paso a la visualización de los resultados obtenidos, los cuales deberán ser certificados, permitiendo identificar cuáles representan conocimiento (interpretación).
- Visualización resultados: comprende la presentación de los resultados obtenidos al completar la aplicación de la técnica de minería de datos seleccionada con anterioridad en el caso de uso minería de datos.
- Validación: identifica la confirmación de la validez de la información obtenida en el estudio, permitiendo discriminar e interpretar los nuevos conocimientos adquiridos.
- Evaluación: representa la comprobación de la relevancia y significado para la gerencia de los resultados presentados.
- Interpretación: representa la explicación e interpretación de los resultados y del conocimiento que se obtuvo a partir de los resultados.
- Difusión: identifica la transmisión de los conocimientos obtenidos una vez validados e interpretados los resultados que se generaron del estudio.
- Gráficos: constituye la presentación de los conocimientos a través de gráficos aclaratorios.
- Reportes: identifica la difusión de la información mediante la emisión de reportes.
- Cuadros/Tablas: representa la propagación de los conocimientos obtenidos mediante la representación de la información en cuadros y/o tablas satisfactorios. En fin, se evalúan los patrones extraídos, para así identificar cuáles de ellos representan conocimiento.
Según como se indica en Jacobson (1998), de cada caso de uso se deriva una interfaz de la aplicación, en esta oportunidad representada por la pantalla del sistema con la cual se espera que el usuario final o actor interactúe. La secuencia de pantallas trata de modelar la interacción típica del usuario desde el proceso de acceso al sistema, la selección de los almacenes de datos, la escogencia de las bases de datos, tablas y atributos deseados, determinación de la técnica de minería de datos hasta la visualización de los resultados. Así, la lectura de las interfaces debe compararse con los casos de uso especificados con anterioridad para obtener de esa forma una visión más amplia de la manera cómo el sistema diseñado actúa a nivel conceptual para el tratamiento de los datos (ver Fig. 2 a 25).
En lo particular, la Fig. 2 muestra la autenticación del usuario al sistema, mientras que la Fig. 3 da la bienvenida al sistema indicando el objetivo del mismo.
Fig. 2. Interfaz de la pantalla Acceso al Sistema.

Fig. 3. Interfaz de la pantalla Bienvenida al Sistema.

La Fig. 4 muestra la pantalla a partir de la cual el usuario puede seleccionar el almacén de datos de donde se extraerá la información o actualizar uno ya existente. Es de especial interés para esta investigación hacer la demostración de una corrida completa del sistema, por tal, el ítem escogido para su explicación es el primero: Nuevo Almacén de Datos, ya que éste constituye el inicio del proceso de extracción de conocimiento. Seguidamente, la Fig. 5 indica las fuentes de los datos, los cuales se pueden obtener mediante la ejecución de un script, la conexión a una base de datos existente o mediante el acceso a un archivo de datos.
Fig. 4. Interfaz de la pantalla Seleccionar Almacén

Fig. 5. Interfaz de la pantalla Agregar Tablas.

La Fig. 6, por ejemplo, muestra la pantalla que se presenta cuando la opción escogida de la fuente de datos es la ejecución de un script. Por su lado, la Fig. 7 muestra la interfaz cuando el acceso se hace desde una base datos, ésta es la opción que se empleará para darle seguimiento al proceso de extracción de conocimiento. En esta pantalla, el usuario debe indicar el servidor de base datos, la base de datos, y los datos de autenticación de usuario. Cuando se conecta, el usuario tiene la posibilidad de escoger cuáles de las distintas tablas que constituyen esta base de datos serán utilizadas para la extracción de conocimiento.
Fig. 6. Interfaz de la pantalla Ejecución de Script.

Fig. 7. Interfaz de la pantalla Conexión con Base de Datos.
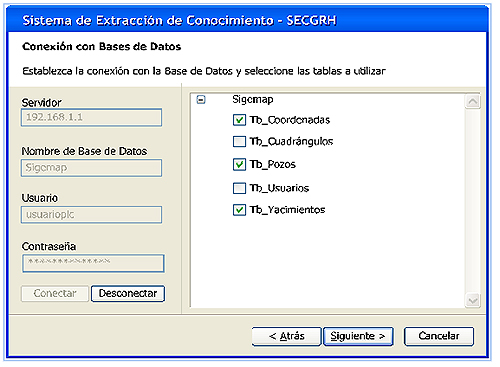
En la Fig. 8 se puede observar la forma como se cargan las distintas tablas que conforman la base de datos seleccionada. El usuario puede escoger una o varias, dependiendo del análisis de datos que desee realizar, así como los atributos que necesitará para el análisis. La Fig. 9 indica cuando el sistema está produciendo la carga del esquema conceptual de las tablas seleccionadas. A continuación, la Fig. 10 muestra los campos que conforman las distintas tablas escogidas, en esta interface el usuario selecciona los campos foráneos necesarios para el cruce de la información entre los distintos contenedores; a partir de los mismos se cargarán los datos requeridos para la extracción de conocimiento. Seguidamente, la Fig. 11 muestra el único almacén de datos generado después del cruce de la información. Este almacén es luego, en la Fig. 12 mostrado en forma de grid para visualizar una parrilla de datos obtenidos de la consulta antes especificada. Luego, en la Fig. 13 se da el tránsito a la depuración de los datos, la cual puede ser por selección, limpieza o transformación, incluso las tres al unísono.
Fig. 8. Interfaz de la pantalla Seleccionar Campos.
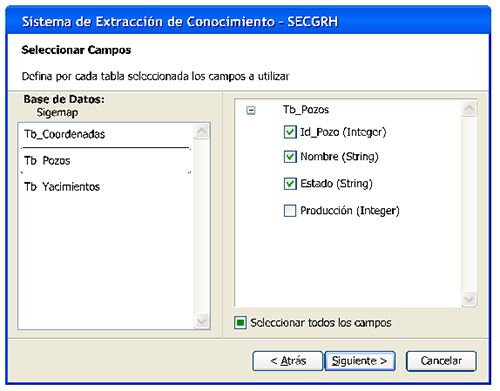
Fig. 9. Interfaz de la pantalla Agregando Tablas.

Fig. 10. Interfaz de la pantalla Claves Foráneas.

Fig. 11. Interfaz de la pantalla Almacén de Datos.

Fig. 12. Interfaz de la pantalla Almacén de Datos-Mostrar Grid.

Fig. 13. Interfaz de la pantalla Depuración de Datos.

La primera depuración de datos ocurre por selección. En esta oportunidad el usuario tiene la opción de seleccionar las tablas que desee y los campos que sean de su preferencia, esto se puede observar en la Fig. 14. Si la depuración de datos es por limpieza, el proceso es un tanto más complejo. En esta oportunidad el usuario puede eliminar todos los registros nulos, eliminar todos los registros con valores inconsistentes o errados agrupados por tipos de datos; y finalmente, eliminar registros con valores inconsistentes o errados indicando tabla por tabla y campo por campo (ver Fig. 15).
Fig. 14. Interfaz de la pantalla Depuración de Datos-Selección.
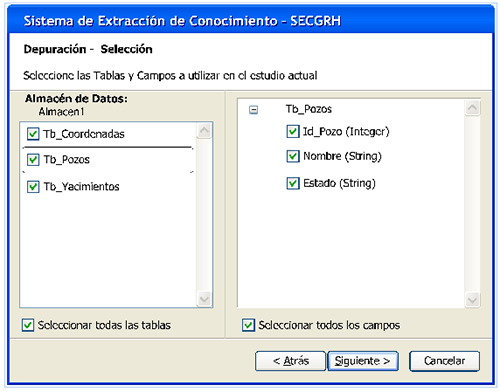
Fig. 15. Interfaz de la pantalla Depuración de Datos-Limpieza.
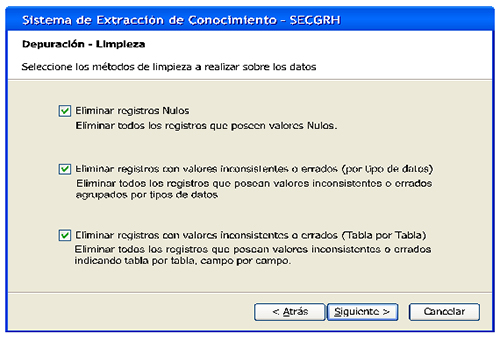
Cuando se trata de una limpieza por registros nulos, la eliminación la realiza el sistema de manera automática, tal como se muestra en la Fig. 16. Si la limpieza es por Tipos de Datos, la Fig. 17 muestra como el usuario puede determinar sobre cuál tipo de dato de la tabla o tablas indicadas y según cuál criterio se va a realizar la limpieza. En el caso particular del ejemplo, se muestra una limpieza por el dato tipo fecha, con el criterio de que las fechas sean menores al 31/12/1900. La Fig. 18 muestra una barra de progreso a partir de la cual se observa la eliminación de los datos que cumplan con el criterio o condición indicada.
Cuando la limpieza es por transformación, la Fig. 19 muestra la interfaz que se presenta al usuario. En esta ocasión, el mismo puede seleccionar la tabla que desee limpiar y los campos de ésta, asimismo puede indicar un criterio y el nuevo valor a partir del cual se realizará la transformación.
Fig. 16. Interfaz de la pantalla Depuración de Datos-Limpieza Registros Nulo.

Fig. 17. Interfaz de la pantalla Depuración de Datos-Limpieza Tipos de Datos.

Fig. 18. Interfaz de la pantalla Depuración de Datos-Limpieza Tablas y Campos.
Fig. 19. Interfaz de la pantalla Depuración de Datos-Transformación.

Paso siguiente es el proceso de minería de datos. En la Fig. 20 el usuario tiene la potestad de elegir la técnica de minería de datos que quiere emplear, la cual puede ser por: (a) reglas de asociación, en la cual el sistema buscará las asociaciones fuertes entre los ítems de información; (b) segmentación, a partir del cual el sistema analiza el agrupamiento de los datos; (c) discriminación, en este caso el sistema compara las características generales de dos o más colecciones de datos; o (d) caracterización, mediante el cual el sistema visualizará un resumen de las características generales del almacén de datos. La Fig. 21 muestra la barra de progreso en la cual el sistema ejecuta la técnica de minería de datos escogida por el usuario.
Fig. 20. Interfaz de la pantalla Minería de Datos.

Fig. 21. Interfaz de la pantalla Ejecución de la Minería de Datos.

A continuación, el sistema arroja las distintas reglas de asociación que ha podido determinar al ejecutar la técnica de minería de datos. La Fig. 22 muestra la interface a partir de la cual la aplicación enlista el conjunto de valores obtenidos luego del proceso de minería de datos, lo cual visualiza mediante reglas. Tales reglas, posteriormente pueden ser chequeadas por el usuario, tal como se observa en la Fig. 23. En esta interface el usuario selecciona los elementos cuyos valores obtenidos considere que tienen validez.
Fig. 22. Interfaz de la pantalla Resultados-Visualización.

Fig. 23. Interfaz de la pantalla Resultados-Validación.

Finalmente, la Fig. 24 visualiza los resultados a través de una tabla, cuadro, gráfica o reporte, los resultados serán presentados según la necesidad del usuario. Los mismos pueden ser guardados para posteriormente ser colocados en informes de gestión que ayuden a la gerencia de hidrocarburos en los procesos de toma de decisiones. La Fig. 25 indica el cierre del programa.
Fig. 24. Interfaz de la pantalla Resultados-Difusión.

Fig. 25. Interfaz de la pantalla Fin del Programa.

5. Por qué código abierto
La idea de realizar este diseño en una filosofía de desarrollo abierto tiene sus serias implicaciones futuras. Actualmente, la mayoría de las aplicaciones que trabajan con este tipo de datos en la industria de hidrocarburos está limitada al software propietario, esto ha hecho que algunos países de América Latina y Europa hayan tenido la necesidad de comprar los derechos de uso de estos softwares a las casas desarrolladoras de los mismos y con ello depender de los procesos de: conversión, adaptación, auditoría, actualización, soporte técnico y operatividad en general. Todo esto como consecuencia de ser softwares genéricos que se hacen con funciones estandarizadas para varias empresas, sin tomar en cuenta las particularidades o especificidades de las mismas.
Lo antes expuesto ha provocado una dependencia tecnológica de las empresas desarrolladoras que se ha mantenido por largo tiempo y ha provocado que las empresas de hidrocarburos mermen su producción de software y estén anualmente pagando costos de licencias por derecho de uso de software, sin la posibilidad de adoptarlo, adaptarlo, mejorarlo y replicarlo con toda libertad.
El proponer este diseño bajo la filosofía de software libre proporcionará ventajas futuras a las empresas de hidrocarburos que conllevarán a alcanzar la soberanía e independencia tecnológica que aspiran muchos países de América Latina y Europa, porque resulta ser un punto de partida necesario para comenzar a realizar aplicaciones hechas en casa, aprovechando con ello el talento nacional en materia informática.
6. Conclusión
KDD es un método que debe ser empleado con carácter de urgencia en las empresas de hidrocarburos para poder determinar patrones de comportamiento impredecibles de la inmensa cantidad de información manipulada por la alta gerencia de estas organizaciones quienes deben oportunamente tomar decisiones eficientes a cerca de la materia petrolera.
SECRH-FOS: Sistema de Extracción de Conocimiento para Empresas de Recursos de Hidrocarburos pensado bajo la filosofía de código abierto, resulta ser un diseño apropiado para incorporar el desarrollo de software con soporte en la metodología KDD y minería de datos en las empresas de esta naturaleza, buscando información más precisa basada en patrones de datos desconocidos y producto de información numerosa y variada que reposa en los almacenes de datos de las grandes empresas que manejan, explotan y administran los recursos de hidrocarburos. Si adicionalmente, estos sistemas de extracción de conocimientos son elaborados tomando en consideración la filosofía de software libre, entonces proporcionarán mayores ventajas competitivas a la industria petrolera, al proponer desarrollo de software que responden a las medidas de sus exigencias, al no depender de las grandes casas matrices que, tradicionalmente, desarrollan estos softwares y al disponer de un producto informático mediante el cual alcanzarían amplio dominio tecnológico.
7. Referencias
Daedalus (2001). Data, Decisions And Language, S.A Minería de Datos. [Página web en línea]. Disponible: http://www.daedalus.es/mineria.
Daza, M. (s.f.) APRIORI I - Un algoritmo para minar reglas de asociación en bases de datos relacionales. [Página web en línea]. Disponible:http://jupiter.umsanet.edu.bo/postgrado/ informática/post/postg6.html.
Hernández, J. (s.f.). Minería de Datos. Trabajo no publicado. España: Universidad Politécnica de Valencia.
Jacobson, I. (1998). Object-Oriented Software Engineering. A Use Case Driven Approach. England: Addison-Wesley.
PMSI (s.f.). El Data Mining. [Página web en línea]. Disponible: http://www.pmsi.fr/dminit1s.htm.